The Transformation & Increased Accessibility of GeoINT
The shift toward accessibility in GeoINT means that all kinds of consumers, be they NGOs, academic outfits, or commercial endeavors, are finding it easier to integrate finished geospatial intelligence into their workflows.
The avalanche of open data, both historical and current, and analyst-freeing automation processes are ensuring that GIS-powered research remains top-shelf intel sitting within reach of an ever-expanding customer base. This touches the study of everything from drone proliferation to coal exports, from drug trafficking to oil infrastructure, from protest analysis to airfield activity.
A government might want to know if new military bases are being built by a neighbor. A private business may want to monitor the construction of a competitor’s new facilities. In these pursuits, change detection is invaluable. Add to that analysts capable of imagery classification, and the makings of an executable plan are clear.
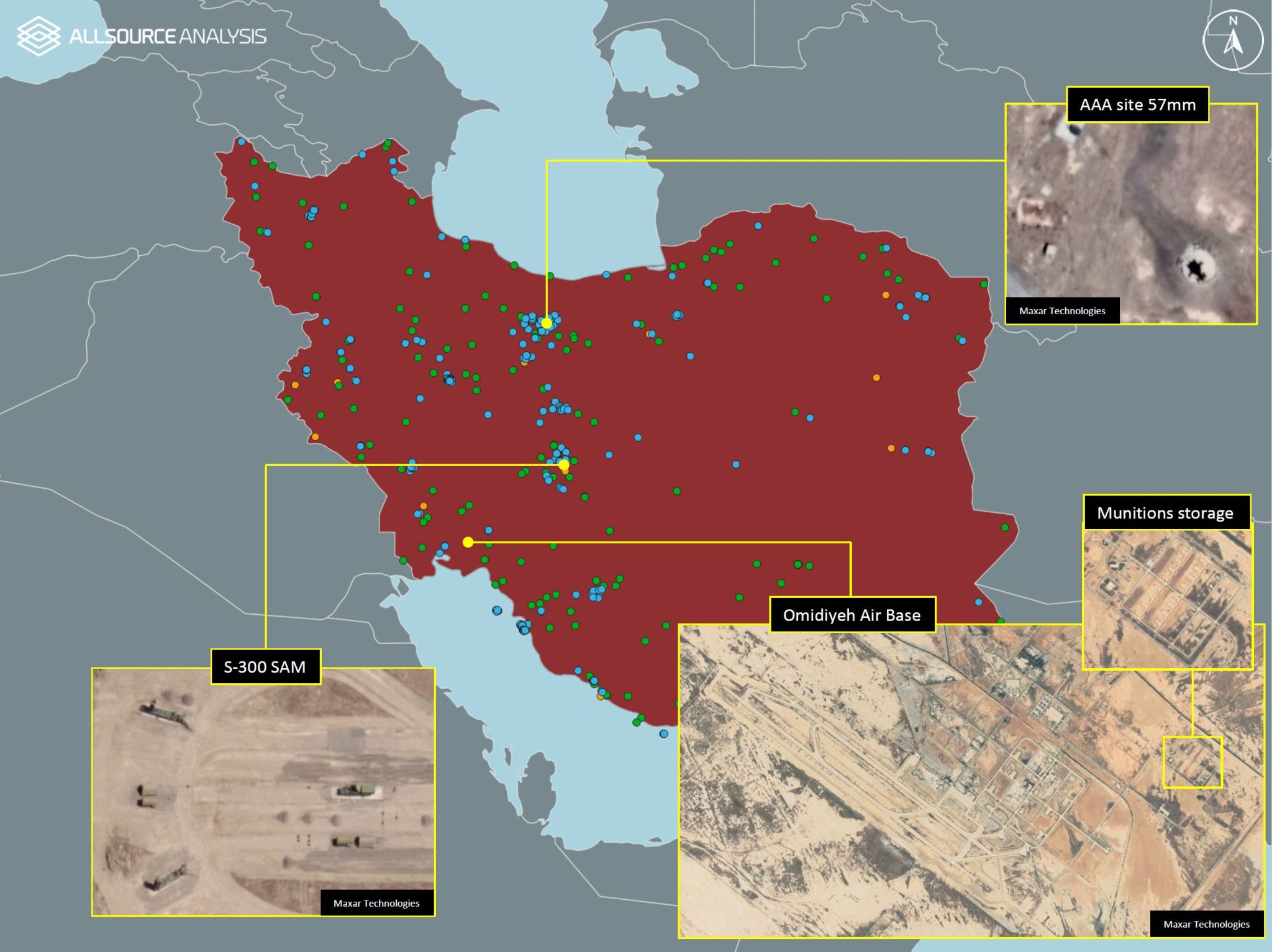
GeoINT datasets can contain various types of information. This one shows the locations of both civilian & military infrastructure in Iran. Image courtesy of AllSource Analysis.
Capturing raw data and turning it into actionable intelligence once required that an entity own (or at least have access to) dedicated satellites and a fully-staffed-and-funded team of expert analysts. Today, as accessibility and demand rise, methods of delivery are transforming, too. Maxar’s recent launch of an analysis-ready data subscription service provides one example, while AllSource Analysis’ network of top analysts and cutting-edge technology provides another.
Tasking imaging satellites to capture something they’re not already capturing is expensive, but the proliferation of satellites as SAR data’s prominence rises means the cost is coming down.
As noted in last week’s post, though, insight is different than information. All the raw data in the world isn’t of much use without specialist knowledge of how to interpret and manage it, and that takes expertise. Without expert eyes, connections between, say, social media data and regional topography might go unnoticed and unleveraged. Fortunately, the capacity to analyze raw satellite imagery and perform image classification is growing as the ranks of capable analysts increase.
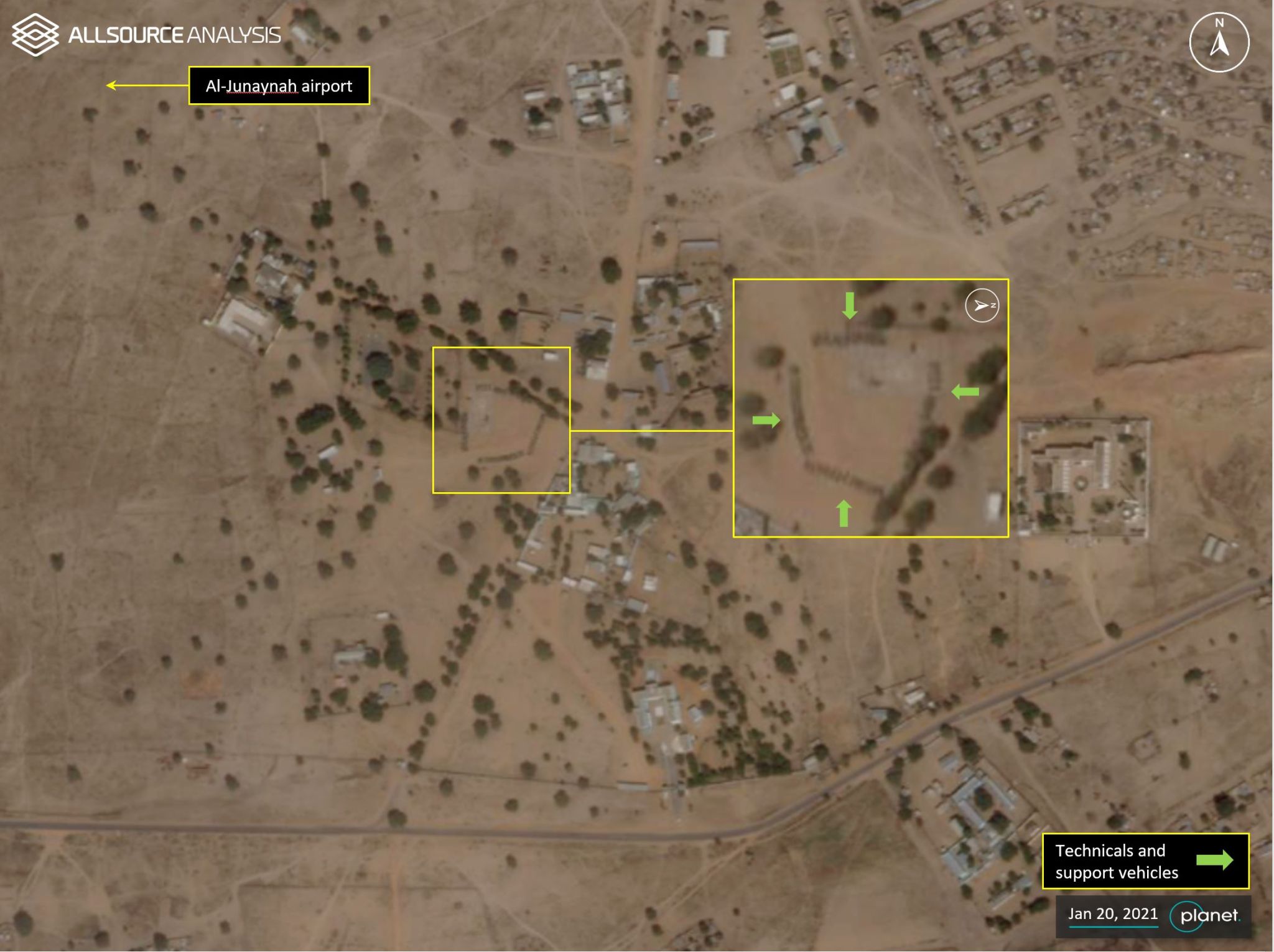
Change detection in imagery is an important part of GeoINT analysis. This image shows an increase in armed vehicles. Image courtesy of AllSource Analysis.
Those analysts are benefitting from a refinement of workflow efficiencies. As AI and machine learning processes speed up previously tedious aspects of the process, the human components are freer to make connections and draw conclusions.
The result of all this? There is more GeoINT data in the hands of more people than ever before.
The Human Role in GeoINT During the Age of Automation
Key Takeaways
- GeoINT agencies collect immense amounts of visual data that, traditionally, must be manually analyzed by humans.
- Automation, machine learning, and AI can help expedite workflows, but over-reliance on machines could diminish analysis quality. An automated eye in the sky can generate images of what’s on the ground, but an understanding of that image’s significance – tactically, economically, socially, or otherwise – is something that requires a human brain.
- Systems that balance human analysts and AI in a complimentary way retain the best of both automation and human cognition.
In 2017, Robert Cardillo, then Director of the National Geospatial-Intelligence Agency announced the NGA’s intention to automate 75% of its image analysis. In 2017 alone, that agency produced 12 million images and 50 million indexed observations, which required immense human work hours. A combination of artificial intelligence, augmentation, and automation was seen as a path toward saving time, money, and effort, while also increasing productivity and accuracy.
Clear benefits aside, automating geospatial intelligence is a more delicate balancing act than it might initially seem.
GeoINT is a discipline that divines meaning from data over time. An automated sweep of an image to run facial recognition is one thing, but repeatedly analyzing a space over time, while considering everything from economics and culture to architectural trends is something that requires human brains and their advanced, flexible cognitive abilities.
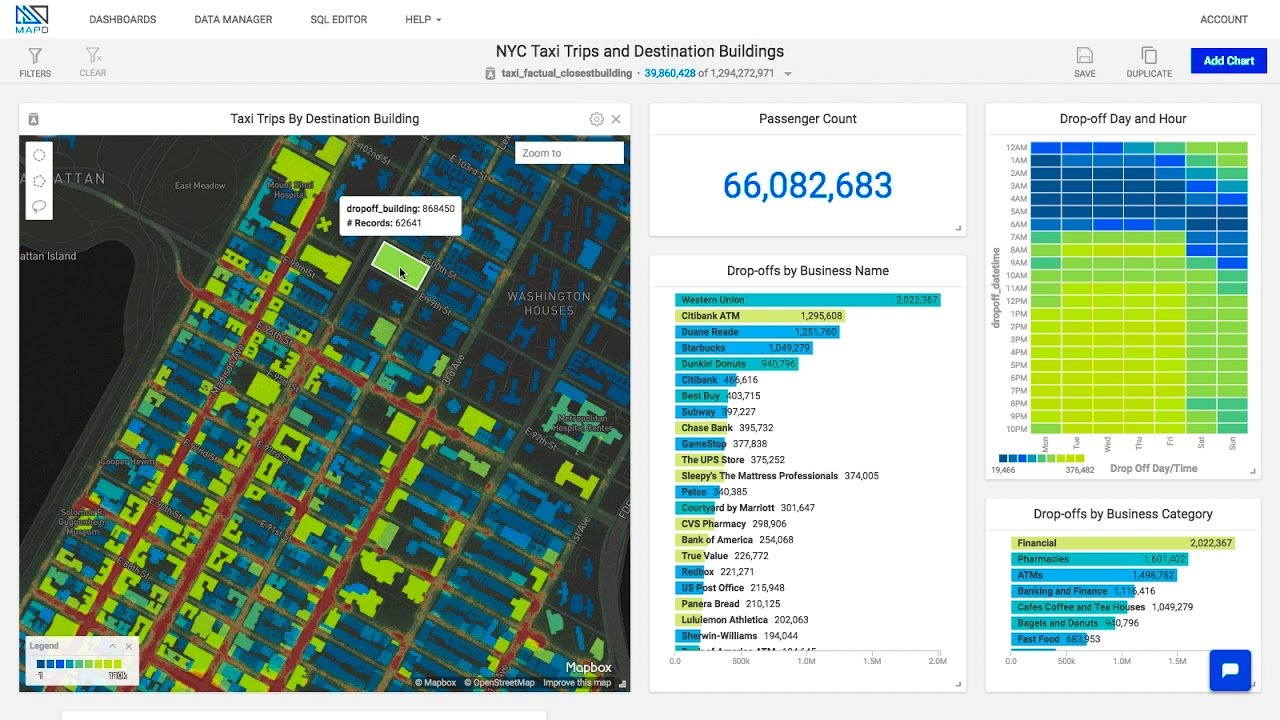
An example of GeoINT analysis with taxi trips and destinations in New York City. Image courtesy of OmniSci.
In our last post, we referenced how workout tracking app, Strava, pivots user data into useable information for city planners. Their data provides remarkable insights, in part, because it was generated by human users keenly interested in finding the ‘best’ routes through a given city. Analysts working on the data they generate know this, too, and it bolsters the value of their end-product.
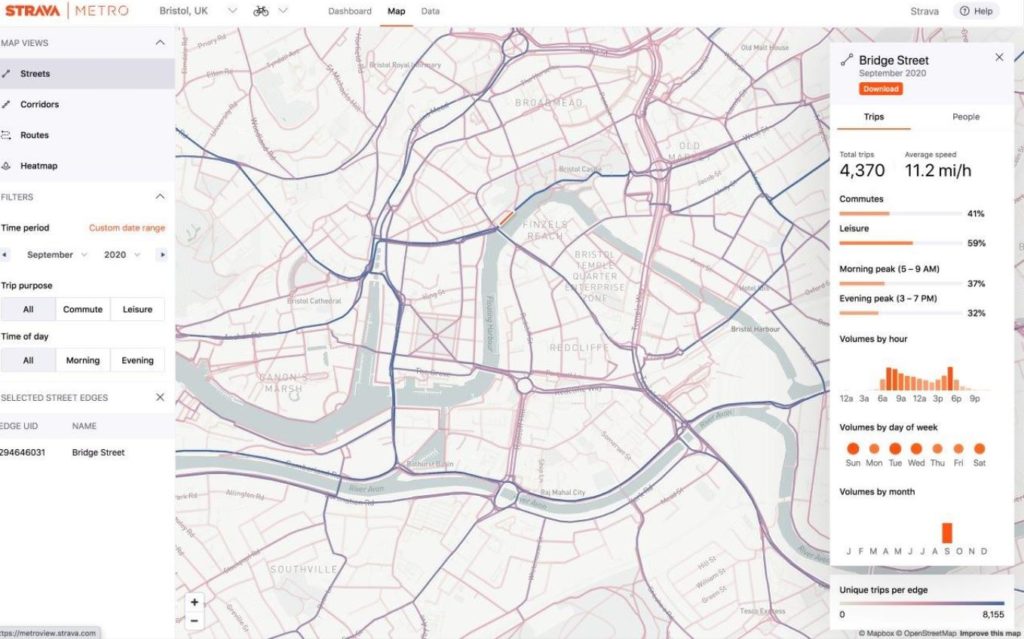
An example of human-generated data in Strava Metro. Image courtesy of Cycling Industry News.
Rather than design systems of automation that seek to circumvent the human element – it is important to have human eyes and brains in the process as verifiers. As this excellent Trajectory Magazine article puts it, an ideal system would follow a ‘human-in-the-loop’ model of analysis.
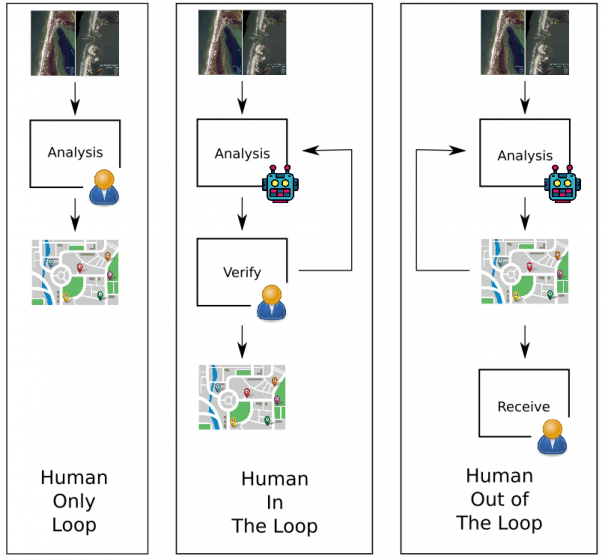
A diagram showing the “Human-in-the-Loop” analysis model. Image courtesy of Trajectory.
Human cognition’s flexibility means our brains can process unexpected information or occurrences. Humans can divine context, see causal relationships inside a space, and draw information from seemingly disparate fields together to form a well-reasoned conclusion. We accrue expertise after experiences. On the other hand, human brains are subject to mental biases and distractibility. Machines, by contrast, can tirelessly perform repetitive tasks and find patterns with ease.
In short: leave the monotony to machines, and free human analysts up to handle the high-level analysis for which their brains are built.
Geospatial Intelligence for All
In 1961, the National Reconnaissance Office (NRO) was established and tasked with maintaining the United States’ intelligence satellite fleet, everything from drawing-board conception to data collection. The geospatial intelligence gleaned from this fleet has been used by the US’s intelligence community (the other four of the US’s ‘big five’ agencies: The Central Intelligence Agency, Defense Intelligence Agency, National Security Agency, and National Geospatial-Intelligence Agency).
The establishment of the NRO pointed to a then-obvious fact of Geospatial Intelligence (GeoINT): governments held the means of data collection, creation, and dissemination.
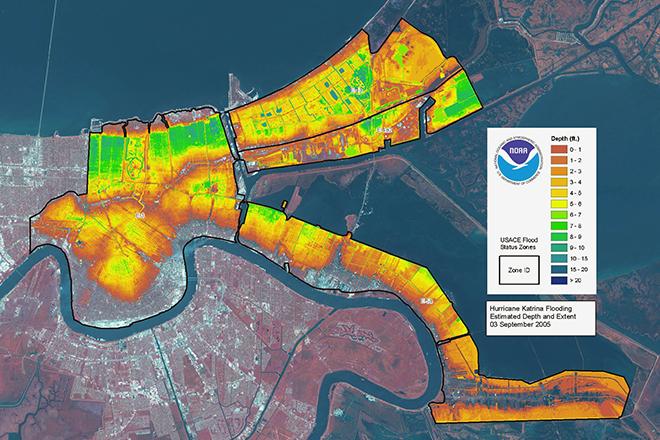
GeoINT image showing LiDAR flood depth data overlaid on a satellite image of New Orleans following Hurricane Katrina. Image courtesy of Penn State University, NOAA, and ESA.
A recent restructuring of responsibilities indicates a shift in that idea. In 2017, the NRO took over responsibility for imagery acquisition from the National Geospatial Intelligence Agency (NGA). The NGA still dictates what imagery is needed, and the NRO collects it, but now utilizes Requests for Information (RFIs) from industry in that pursuit.
In 2019, the NRO awarded significant contracts to Maxar, BlackSky, and Planet in an effort to better understand the quality, quantity, and kinds of available commercial data. As these kinds of interactions between the US government and commercial entities continue, the intelligence community will learn more about what commercial capabilities exist and the commercial sector will hone its understanding of what imagery and intelligence the NRO might require next.
This signals a sea-change from government-generated GeoINT to commercially produced data and analytics.
Why the shift, though? As spatial data, machine-learning, and other aspects of GeoINT have grown in the commercial sector, the government sees potential for data superior to that generated by government departments.
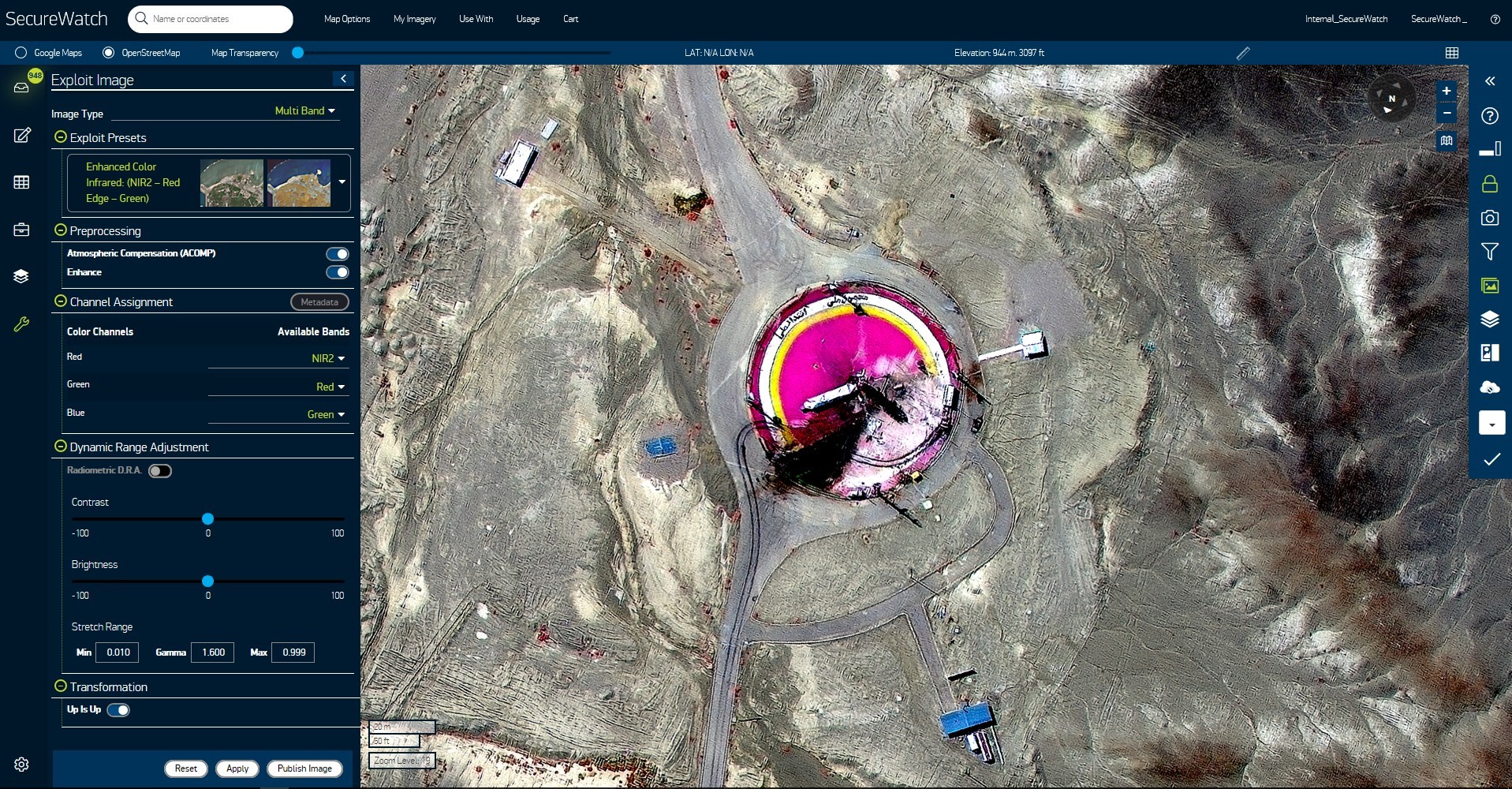
Analysis tools in programs like Maxar’s SecureWatch (pictured here) enable users to perform multi-spectral analysis of different events, like this failed missile launch at Semnan Space Facility in Iran in 2019. Image courtesy of Maxar.
This isn’t just a federal-level dynamic; municipalities working on city transportation plans provide a clear example of the shift from public to private geospatial data generation. In the past, when a city decided to build new roads or modify some aspect of its transportation system, a mapping survey team might have gone out to collect raw data. Today, that data will likely come from a private company’s vast stores of user-generated geospatial data.
Companies like Strava Metro, a product of workout tracking app Strava, use aggregates of user data (stripped of identifiers) to illustrate popular walking, running, and biking routes through cities. Individual athletes can use this data to find new routes (or, in the age of Covid, routes that avoid others runners). In the hands of municipalities, however, this data can be used to better inform city planning efforts when new bike lanes and recreation loops are being worked on. Data from Strava Metro gets into as granular of details as which way people travel down certain streets. Cyclomedia, a Dutch company providing street-level data created with LiDAR and traditional imaging methods, takes a similar approach, marketing their information to utility companies.
The same is true for data originating from commercial efforts to automate vehicles. To ‘teach’ Cadillacs to drive autonomously on highways, aspects like slope of road, lane delineations, and other data were collected by Ushr, Inc. In-city autonomous driving would require equipping luxury vehicles with cumbersome LiDAR devices, which violate Cadillac’s aesthetic principles, but city busses have more freedom in that regard. The data Ushr generated could very well be used in service of making a fleet of city vehicles autonomous.
In city environments increasingly rich with active pedestrians, autonomous vehicles, and an enormous amount of user-generated geo-tagged GeoINT, it seems more and more likely that planners at every level of government will wind up turning to privately-created data and services to continue building the cities and communities of the future.